# --- Environment and Library Setup ---
import os
import json
import pprint
from io import BytesIO
from PIL import Image
from IPython.display import display
from google import genai
from google.genai.types import Part
from dotenv import load_dotenv
load_dotenv()
GOOGLE_API_KEY = os.environ.get("GOOGLE_API_KEY")14 Multimodal Models
14.1 Introduction
Large Language Models (LLMs) have undergone a remarkable evolution, expanding beyond their original text-based foundations to become truly multimodal systems capable of understanding and generating content across different data types. This transition represents a significant leap forward in artificial intelligence, as these models now seamlessly process and interpret images, audio, and video alongside text.
What makes multimodal LLMs particularly powerful is how they leverage their general intelligence—originally developed for understanding natural language—to solve complex tasks across various modalities. The same reasoning capabilities that allow these models to interpret nuanced text now enable them to analyze visual scenes, transcribe speech, and comprehend video content with remarkable accuracy.
While specialized tools have long existed for tasks like optical character recognition (OCR), image classification, or speech processing, multimodal LLMs bring something uniquely valuable: common sense understanding. Rather than treating each modality as an isolated technical challenge, these models approach problems holistically, drawing connections between concepts across different forms of data. For example, when analyzing an image, they don’t just identify objects but understand their relationships, context, and implications—much as a human would.
Perhaps most transformative is how these models democratize complex tasks through natural language interfaces. Instead of requiring specialized programming knowledge or technical expertise, users can simply describe what they want in plain English. Whether extracting structured data from documents, editing images, or analyzing video content, the core instructions can be written conversationally. This dramatically reduces the amount of code needed and makes sophisticated AI capabilities accessible to a much broader audience, including economists and researchers without extensive technical backgrounds.
In this chapter, we’ll explore practical applications of multimodal models for economic research, demonstrating how they can extract insights from diverse data sources with minimal technical overhead.
14.2 The Evolution of Data in Economic Research
Traditionally, economic analysis has relied heavily on structured numerical data—time series, panel data, and cross-sectional surveys. However, in today’s digital age, the sources of economic information are expanding. Policy documents, news media, social media posts, and even video advertisements now contribute to a rich, multifaceted picture of economic behavior.
Recent advances in machine learning now allow us to analyze this diverse array of data. Multimodal models can combine textual, visual, and auditory signals into a unified analysis framework. For instance, models that perform OCR can transform images of printed reports into machine-readable text, while video analysis models can detect product placements in commercials. Ultimately, this integration enhances our ability to assess market trends, monitor economic indicators, and inform policy decisions.
14.3 Preliminaries
Before diving into detailed examples, it is crucial to understand the core components of our toolkit.
14.3.1 The GenAI API
Google’s Generative AI API (GenAI) provides a powerful interface for working with multimodal models. Understanding its structure is essential for effective implementation:
Multipart Prompts: Unlike traditional text-only APIs, GenAI accepts prompts composed of multiple parts with different modalities. A single prompt can contain:
- Text instructions (as strings)
- Images (as binary data or file paths)
- Video content (via URLs or file paths)
- Audio clips (as binary data or file paths)
This multimodal capability allows you to construct complex queries that combine different data types, such as “analyze this image and extract data according to this schema.”
Response Structure: When the API returns a response, it provides:
- A list of
candidates(alternative responses) - Each candidate contains
contentwith multipleparts - Parts can include text, images (as inline binary data), or other modalities
- A list of
For example, a typical response structure might look like:
response.candidates[0].content.parts[0].text # Access text in the first part
response.candidates[0].content.parts[1].inline_data # Access binary data (e.g., image)This structure allows the API to return rich, multimodal responses that can include both explanatory text and generated visual content. When working with the examples in this chapter, you’ll frequently iterate through these parts to extract the different components of the response.
14.4 PIL: Python Imaging Library
The Python Imaging Library (PIL) was originally developed as a powerful tool for image processing in Python. However, the original PIL project stopped development in 2011. Pillow emerged as a “fork” or community-maintained continuation of PIL, ensuring the library remained compatible with newer Python versions while adding modern features and bug fixes. Today, when we import and use PIL in Python, we’re actually using Pillow behind the scenes. In this chapter, we’ll primarily use PIL for loading, displaying, and saving images when working with multimodal models.
14.4.1 Basic Image Operations
Here are some common operations you’ll use frequently:
# Import the library
from PIL import Image
from IPython.display import display
# Loading an image
img = Image.open("path/to/image.jpg")
# Display the image (useful in notebooks)
display(img)
# Basic image information
print(f"Format: {img.format}")
print(f"Size: {img.size}")
print(f"Mode: {img.mode}") # RGB, RGBA, etc.
# Saving an image
img.save("output_image.png") # Can convert formats by changing extension14.4.2 Other Capabilities
While our focus will be on basic loading and saving, PIL offers many other powerful features:
- Image manipulation: Resize, crop, rotate, and flip images
- Color transformations: Convert between color modes, adjust brightness/contrast
- Drawing: Add text, shapes, and other elements to images
- Filters: Apply various filters like blur, sharpen, and edge detection
- Format conversion: Convert between different image formats (JPEG, PNG, GIF, etc.)
- Pixel-level access: Read and modify individual pixels
When working with multimodal models, PIL serves as the bridge between the binary image data returned by APIs and the visual representation we can display and analyze.
14.5 Extracting Structured Data from Scanned Documents
One common task in economic research is extracting structured information from unstructured documents, such as scanned reports or receipts. Optical Character Recognition (OCR) enables this by converting images of text into machine-readable data. LLM-based models have vastly improved the OCR capabilities available to us. First their common-sense allows them to better guess the text when there is ambiguity. Second, as we shall see, they can not only convert image to text, they can understand and extract the text in a structured form that makes it much more usable for further data analysis.
This added power comes with a cost too. Like elsewhere, LLMs can hallucinate on OCR tasks too, specially when asked to work with poor quality images. In the absence of a clear signal, or for unexpected data, they may replace the content of the document with their statistical beliefs. Careful quality control is essential when using them.
14.5.1 The Economic Use Case
Imagine you have a collection of scanned financial statements or policy documents. Manually transcribing these documents is both time-consuming and prone to error. With OCR powered by machine learning, you can automate this extraction process, ensuring that key economic indicators are quickly and accurately captured.
14.5.2 A Practical Example: Extracting a Quotation
Below is a practical example that demonstrates how to extract structured data from an image. In this case, the image contains a quotation for a car. Different dealerships may format their quotation in different ways. However we want to extract the data from the quotation in a structure we specify, so that data from a large number of quotations can be collected together and processed in a uniform way.
14.5.2.1 Code Walkthrough
First, we set up our environment and import the necessary libraries. We load the API key from a .env file as in the previous chapter. There we also discussed the alternative of using the built-in Secrets facilities if you are working on Google Colab.
Next, we define a data model using Pydantic to specify the expected output structure.
# --- Define a Data Model for Structured Output ---
from pydantic import BaseModel, Field
class PriceComponent(BaseModel):
name: str
value: float
class CarQuote(BaseModel):
date: str = Field(description="ISO 8601 format date")
dealer_name: str
car_manufacturer: str
car_model: str
ex_showroom_price: float
total_price: float
all_price_components: list[PriceComponent] = \
Field(description="The breakup of the price. Discounts to be given negative values")The use of Field is new. It is a feature of Pydantic to let us provide additional information beyond the type. We use the description attribute to add a description which will guide the LLM as to the expected values for the field. We ask that the date be in ISO 8601 format which is a standard YYYY-MM-DD based format
After defining the data model, we set up the prompt that instructs the API on what to extract from the image. The prompt, though simple, guides the model to generate output according to the specified JSON schema.
ocr_prompt = """
This is a quotation for a car.
Extract data from it in the specified JSON schema.
Provide the ex-showroom price separately as well
as a part of all-price components.
"""Next, we load the image containing the quotation. The image is opened using PIL, and we display it to confirm that it has been loaded correctly. This step is especially useful when working interactively in a notebook environment.
ocr_path = "/home/jmoy/code/Py book 2024/book_content/static/images/Quotation.jpg"
ocr_in_image = Image.open(ocr_path)
display(ocr_in_image)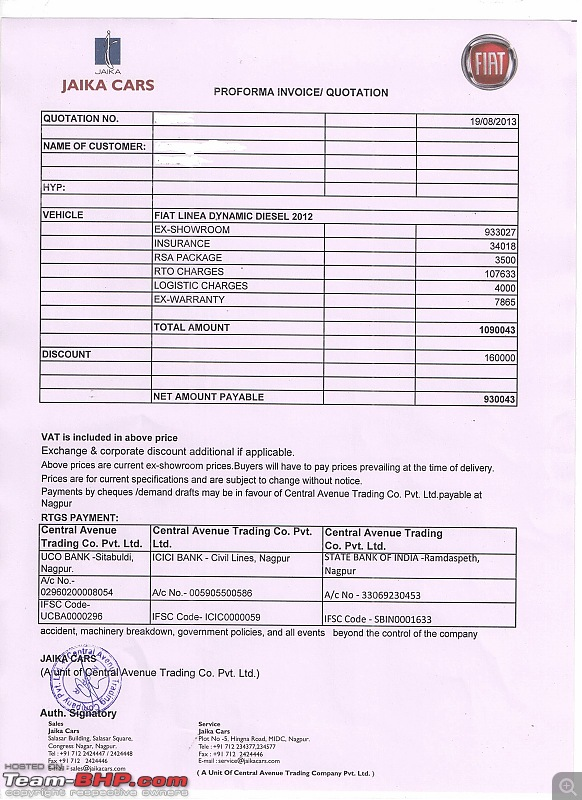
We open the image file and read in its contents. Note the string "rb" for the open mode. r is for read and b is for binary. Adding the b tells Python that the content of the file should not be treated as text but should be passed on as an unprocessed set of bytes.
with open(ocr_path, "rb") as f:
in_ocr_bytes = f.read()With the image data and prompt prepared, we initialize the GenAI API client and send a request to generate the structured output.
The contents argument is now a list with two entries.
- The first entry is our text prompt, as a string.
- The second entry is our image. We use the constructor of
Partto pass in the bytes of the file as well as the MIME type, which forjpgfiles isimage/jpeg(JPEG being the name of the image compression algorithm used injpgfiles)
client = genai.Client(api_key=GOOGLE_API_KEY)
response = client.models.generate_content(
model="gemini-2.5-pro-exp-03-25",
contents=[
ocr_prompt,
Part.from_bytes(data=in_ocr_bytes, mime_type="image/jpeg"),
],
config={
'response_mime_type': 'application/json',
'response_schema': CarQuote,
'seed': 10
}
)Finally, we parse the JSON response and print it. This final step converts the API’s output into a usable Python dictionary.
res = json.loads(response.text)
pprint.pprint(res){'all_price_components': [{'name': 'EX-SHOWROOM', 'value': 933027.0},
{'name': 'INSURANCE', 'value': 34018.0},
{'name': 'RSA PACKAGE', 'value': 3500.0},
{'name': 'RTO CHARGES', 'value': 107633.0},
{'name': 'LOGISTIC CHARGES', 'value': 4000.0},
{'name': 'EX-WARRANTY', 'value': 7865.0},
{'name': 'DISCOUNT', 'value': -160000.0}],
'car_manufacturer': 'FIAT',
'car_model': 'LINEA DYNAMIC DIESEL 2012',
'date': '2013-08-19',
'dealer_name': 'JAIKA CARS',
'ex_showroom_price': 933027.0,
'total_price': 930043.0}Looks like the model has successfully extracted the data. Now we can use this procedure in a loop to mechanically extract data from a whole set of quotations and obtain a uniformly structured result.
14.6 Editing Images
Just like other economic data, images also do not come to economists in a ready-to-use format. Often features of interest must be extracted from images. Large multimodal models can help here too.
14.6.1 Example: Extracting identity photos from snapshots
Suppose you have a set of snapshots taken in the field. You would like to extract just faces from them—say because you want to issue each of your respondents an identity card on your next visit. Image procession features of multimodal models can help you automate the task.
14.6.1.1 Code Example
The first steps are the same as before. We open and display the image:
imedit_path = "/home/jmoy/code/Py book 2024/book_content/static/images/selfie.jpg"
ed_in_image = Image.open(imedit_path)
ed_in_image.thumbnail((400,400))
display(ed_in_image) # Quick check to ensure the image loads correctly
Next we write the prompt to clearly specify what we want. Not how specific we are being in our language.
imedit_prompt = """
Identify the human face.
Extract it and put it in a square passport photo
where the face forms about 80% of the image.
Erase anything not a part of the human whose
face is selected.
Fill in missing parts of the human minimally.
Make the background solid white.
"""We send our request using the same steps as in the last example.
with open(imedit_path, "rb") as f:
in_edimage_bytes = f.read()
# Initialize the GenAI API client.
client = genai.Client(api_key=GOOGLE_API_KEY)
# Request the API to perform the image editing based on the prompt.
response = client.models.generate_content(
model="gemini-2.0-flash-exp-image-generation",
contents=[
imedit_prompt,
Part.from_bytes(data=in_edimage_bytes, mime_type="image/jpeg"),
],
config={
'response_modalities': ['Image','Text'],
'seed': 110
}
)We are expecting to receive an edited image. To find it we iterate through the parts of the content of the first of the response candidates (there is going to be only one since we did not ask for multiple candidaates). If we find a part with inline_data we assume it is the image, and obtain the contents of the image from the data attribute of inline_data. If we wanted to be really sure we could have checked the mime_type attribute of inline_data and checked that it belonged to an image type.
Having obtained the bytes, we could have saved them to a file, using the returned mime type to figure out the correct filename extension to use. But since we also want to display the image here, we convert it to a PIL image. To help in this we use the BytesIO class from the standard io library. This class takes a set of bytes and makes it appear like the contents of a file, so that it can be passed to other functions which expect a file, like Image.open. Let’s see what we get:
from io import BytesIO
import PIL
out_edimage = None
for part in response.candidates[0].content.parts:
if part.text is not None:
# This branch can provide textual feedback from the API.
print(part.text)
elif part.inline_data is not None:
out_edimage = PIL.Image.open(BytesIO(part.inline_data.data))
# Display the final edited image.
out_edimage.thumbnail((200,200))
display(out_edimage)
Looks like Gemini delivered again.
14.7 Extracting Insights from Videos
Video content has become an increasingly important data source in economic research. For example, marketing analysts might study product placements in media to understand consumer behavior, while political economists might analyze televised debates to gauge public sentiment. Carefully watching videos and annotating them is a daunting task. By mechanising video content, LLMs promise to make it easy an cheap, allowing economists to trawl through large collections of videos to construct datasets.
14.7.1 Example: Detecting Product Placements in Videos
Consider the task of identifying product placements in Bollywood songs. We could have uploaded video content like we did with images, but Gemini very helpfully can directly access YouTube videos, so we go with that.
We begin by defining our data schema:
class ProductPlacement(BaseModel):
start_timestamp: str
end_timestamp: str
brand: str
brand_category: str
actor_name: str = Field(description=
"name of actor (male or female) using or wearing product with the brand")Since the model may not be able to identify all actors, we make the actor name optional, using the Optional from the standard library typing module.
Next, the prompt:
video_prompt = """
Find all instances of identifiable brand logos or
products of known brands in the video and return
your results in the given schema.
Give instance only when the branding is clearly seen on the apparel of or on a product being used by an actor (male or female) and appears continuously on the screen for one second or more. False positives are much worse than false negatives.
"""We make the API call. This time using the from_uri method of Part to construct a part from the URL of the video. The video we are trying it on is the title track of the movie Kuch Kuch Hota Hai.
response = client.models.generate_content(
model="gemini-2.5-pro-exp-03-25",
contents=[
video_prompt,
Part.from_uri(file_uri="https://www.youtube.com/watch?v=bKZTnnFU9HA",
mime_type="video/mp4")
],
config={
'response_mime_type': 'application/json',
'response_schema': list[ProductPlacement],
'seed': 110
}
)Let’s see what we got:
res = json.loads(response.text)
print(f"{len(res)} instances of product placement detected")
pprint.pprint(json.loads(response.text))8 instances of product placement detected
[{'actor_name': 'Shah Rukh Khan',
'brand': 'Polo Sport',
'brand_category': 'Apparel',
'end_timestamp': '1:53',
'start_timestamp': '1:11'},
{'actor_name': 'Shah Rukh Khan',
'brand': 'GAP',
'brand_category': 'Apparel',
'end_timestamp': '2:06',
'start_timestamp': '2:01'},
{'actor_name': 'Shah Rukh Khan',
'brand': 'Lacoste',
'brand_category': 'Apparel',
'end_timestamp': '3:07',
'start_timestamp': '2:53'},
{'actor_name': 'Shah Rukh Khan',
'brand': 'Polo Sport',
'brand_category': 'Apparel',
'end_timestamp': '3:43',
'start_timestamp': '3:41'},
{'actor_name': 'Kajol',
'brand': 'DKNY Jeans',
'brand_category': 'Apparel',
'end_timestamp': '4:01',
'start_timestamp': '3:49'},
{'actor_name': 'Shah Rukh Khan',
'brand': 'Nike',
'brand_category': 'Apparel',
'end_timestamp': '4:12',
'start_timestamp': '4:07'},
{'actor_name': 'Shah Rukh Khan',
'brand': 'Polo Sport',
'brand_category': 'Apparel',
'end_timestamp': '4:35',
'start_timestamp': '4:18'},
{'actor_name': 'Kajol',
'brand': 'Reebok',
'brand_category': 'Apparel',
'end_timestamp': '5:05',
'start_timestamp': '5:03'}]I’m not sure there was so much product placement going on in 1990s Bollywood. Check the video!
14.8 Conclusion
We have only scratched the surface of what you can do with multimodal models. The exercises suggest more tasks and beyond that your imagination is the limit. Machine learning is going to open up a whole new content of structured data for economists.
But the continent is not going to be entirely benign. We are going to be menaced by the dangers of hallucinations and biases. In these early days, it will be especially important to have controls in the form of sanity checks and more formal comparisons against independent human expert codings to ensure the quality of our data.
14.9 Exercises
There is more to image understanding that just OCR. Try other image classification or description tasks. For example, given the photograph of a traffic signal, ask the model to classify whether the signal if working or not working and if working then identify the light which is on.
If you wanted to run OCR on a bunch of quotations than just one, you would have to go through files in a loop. Learn about Python facilities for working with ZIP archives and iterating through the list of files in a directory.
Experiment with image generation.
One input type we have not touched upon is audio. Transcribe an audio interview.
Use a model to segment a video, say, based on the speaker, or the topic of discussion.
Experiment with prompts to see how strict or loose you have to be to get the best results.